How Does a Website Work (simple but detailed explanation)
We all visit many sites during our day for information or fun. But how these websites actually work technically?I will provide you more details in the next paragraphs but the short answer is:
1.) We type the URL (ex. buycompanyname.com) in our browser (like chrome).
2.) The browser checks the IP related to the domain by using the domain name system.
3.) When the correct IP (the address of another computer on the web) is found, a server (the other computer) that stores all the website data we need, returns the information back to our browser.
4.) Our browser reads the info that it gets and it presents visually to us. The server has sent text, images, video, and graphics back to us in addition to some instructions (code) to the browser how the whole data will be presented.
What is a Website?
A website is the total files, documents, and different types of resources such as images or videos that are stored in a server and they are available on the web if someone requests to see a part of them via his browser.
You can compare a website like a dedicated big folder in your pc with many sub-folders that contain different documents and files. When someone tries to reach a specific page (web page) on a website then he does exactly that, he searches for a specific document in a sub-folder.
The only difference is that you don’t have your folders available on the web (although you can do that).
A Website Technical Structure Example
A webpage (such as this post) has 3 components/technologies behind what we actually see in our browser: HTML (Hypertext Markup Language), CSS ( Cascading style sheets) and sometimes Javascript (a computer programming language).
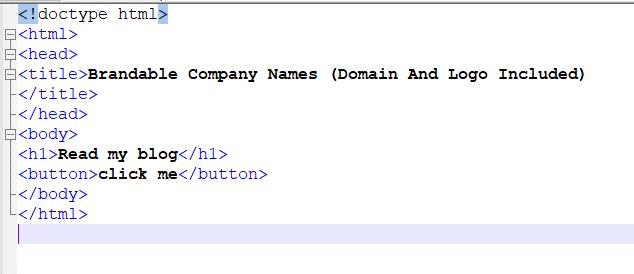
Html is written in a document and informs our browser what is the general structure such as the head of our webpage, the title, the body, the paragraphs, and many other options. This is how a simple .html document looks:
The HTML code is responsible to guide the browser where it can find the rest files/documents needed for the full webpage display. These can be the CSS, javascript documents or images and videos.
Try to visit any website and then press right-click on your mouse. You can inspect the code by choosing “view source” code. There you will see a more advanced HTML code.
CSS adds the style to our webpage, for example, what color would be in the background. Other options can be the size of the text, what would be the distance between the paragraphs and everything related to the style of our page.

This is how a simple CSS document looks like. It can be included within HTML document but for simplicity purposes and following the best programming templates it is usually stored in a different document and that file extension ends in .css.
The last component is the most complicated one and it is called javascript. This programming language is used for graphics and also for the dynamic parts of a web page. For example, what will happen after a user clicks a button or submit a form. Another example is what happens in the webpage related to the mouse cursor of the user (we can change the color of the text).
Usually, the same principle is applied as we did with the CSS document. The best practice is to keep the javascript in different documents/folders than HTML one.
What happens When I Access a Site?
Now that we have a better understanding of what is a site let’s see what happens when we type an URL in our browser.
I type www.buycompanyname.com in chrome. If we type buycompanyname.com then we see www to be added in that case too (because I have set it that way). You have an option to use www. or not since typically www. is a subdomain of buycompanyname.com.
*recent update from chrome: for better user experience Chrome doesn’t add www. anymore or https:// but under the surface, the URLs work like they used to do. Double click on the URL and you can see the full display as it should be.
Just for the records for technical issues is better to use www. when you have many subdomains like email.buycompanyname.com or login.buycompanyname.com for performance issues (it is related to the use of cookies). If you don’t use sub-domains it considers the same but the “naked” domain is shorter and better in the eyes of internet users.
Then we see that https:// is also added to our domain. HTTPS is a protocol that defines how the data between your browser and the server is exchanged. HTTPS means Hypertext Transfer Protocol.
The browser doesn’t understand what is the domain we typed so it searches on the internet what does that domain mean in numbers (the language that machines understand).
After this step browser checks in many different places to find out this detail. The whole process takes milliseconds depending on what level the browser will find the information it seeks. This is done by a single or multiple DNS queries (or requests).
DNS query happens when a computer asks a server for the IP related to a specific domain name.
First, it checks its own browser cache. If you have visited that site previously there is a big chance that your browser already knows the IP related to the domain.
The second place that the browser will check is your operating system such as Windows or MAC since the operating systems maintain a cache too of some domain name system records.
After that router is the next place that has this kind of record too.
If the previous try is unsuccessful, the browser will check your internet service provider (like Verizon) cache. Internet service providers have their own machines with many more records about domains and their related IPs. These computers are called Domain Name System Resolvers.
The next level is actually a root server in case the resolver doesn’t have the IP we seek. The root servers are spread around the world owned by reputable organizations such as NASA. The route server will redirect the query to a TLD server. In our case the server related to the .com domain.
The TLD server knows which is the authoritative name server (our final step) that has all details about the domain and especially the one we most need the IP address!
TLD server passes the details to the resolver and then to the browser. Since now our browser knows the IP address of the server tries to establish a connection by sending a different type of request.
This time the browser asks from the server to send all the details of a webpage and our browser presents the final results to us. The type of request, in that case, is called https GET since we ask from the server to get information now that we know where is the server located on the web (IP address).

Use your mouse right-click > inspect > network > ctrl + R. You will see something similar to the picture I share with you above.
I will explain what each header means in the screenshot. “Status” is the response code and in our case 200 means that the request was successful. 404, for example, means that nothing found on the server.
“Type” is related to the resource. For example, if we requested an image or a specific type of document. “Initiator” is what was the cause for the specific resource to be requested.
“Time” is how much time we spend from requesting the specific resource until we get it. “Waterfall” is some graphics that explain a bit further the specific request.
What do you need for a website?
You need 2 things for a website: domain and hosting. You can read in my previous blog post how and where you can get both at a good price.
You need a domain for the people to easily find you on the internet. You need hosting for storing all the data that will make a website working properly. The data can be images, files, videos and the code for your website.
Typically you can even use your pc to store all the data needed but you need to have it open 24 hours a day or else your website would not be available for the public. The hosting provider uses a specific type of computer that we call servers to store your data.
Even if you are not a programmer you can use free software called content management system and create a visually good website. The most successful content management system is WordPress and almost all hosting providers offer this option.
Typically you can store your website for free but you use a subdomain of a domain that someone else owns such as thisismywebsite.wordpress.com or thismywebsite.blogspot.com. Don’t visit those sites I just randomly present some examples without knowing if these subdomains are used.